As your codebase grows, it can become harder and harder to implement new features and manage the complexity of your application. Similarly, as the engineering org grows, there are increasing demands on teams to build new features and iterate application logic in parallel.
One of the key tools to managing this friction is to decompose your system into separate services. This is the basic motivation behind the move to microservices. However, once we decompose into multiple services, we usually have to figure out how to synchronize state between our services. The classic approach is to have each service expose an API which other services can invoke, and pass state over these API channels. Unfortunately this usually leads to high coupling between services as any change in the API contract of one service may require updating N other services that depend on that API.
I have found event sourcing to be very useful for synchronizing state between services while maintaining only loose coupling between those services. Event sourcing is a fancy name, but it’s really just an implementation of the observer pattern which is incredibly common. The basic idea is to have observer B anonymously register
interest in state changes with source A. Whenever state changes in source A it broadcasts these changes, as a series of event messages, to all observers. The classic Javascript addEventListener API is an example of the observer pattern that most people will be familiar with.
This keeps the target and observer decoupled because the generic “register for event notification” and “deliver change event” APIs never change. (However, note that the specific event message shapes will often create an implied contract between the source and the observer. If the specific shapes of events change then a fault may occur with a downstream observer that is still expecting the old shape.)
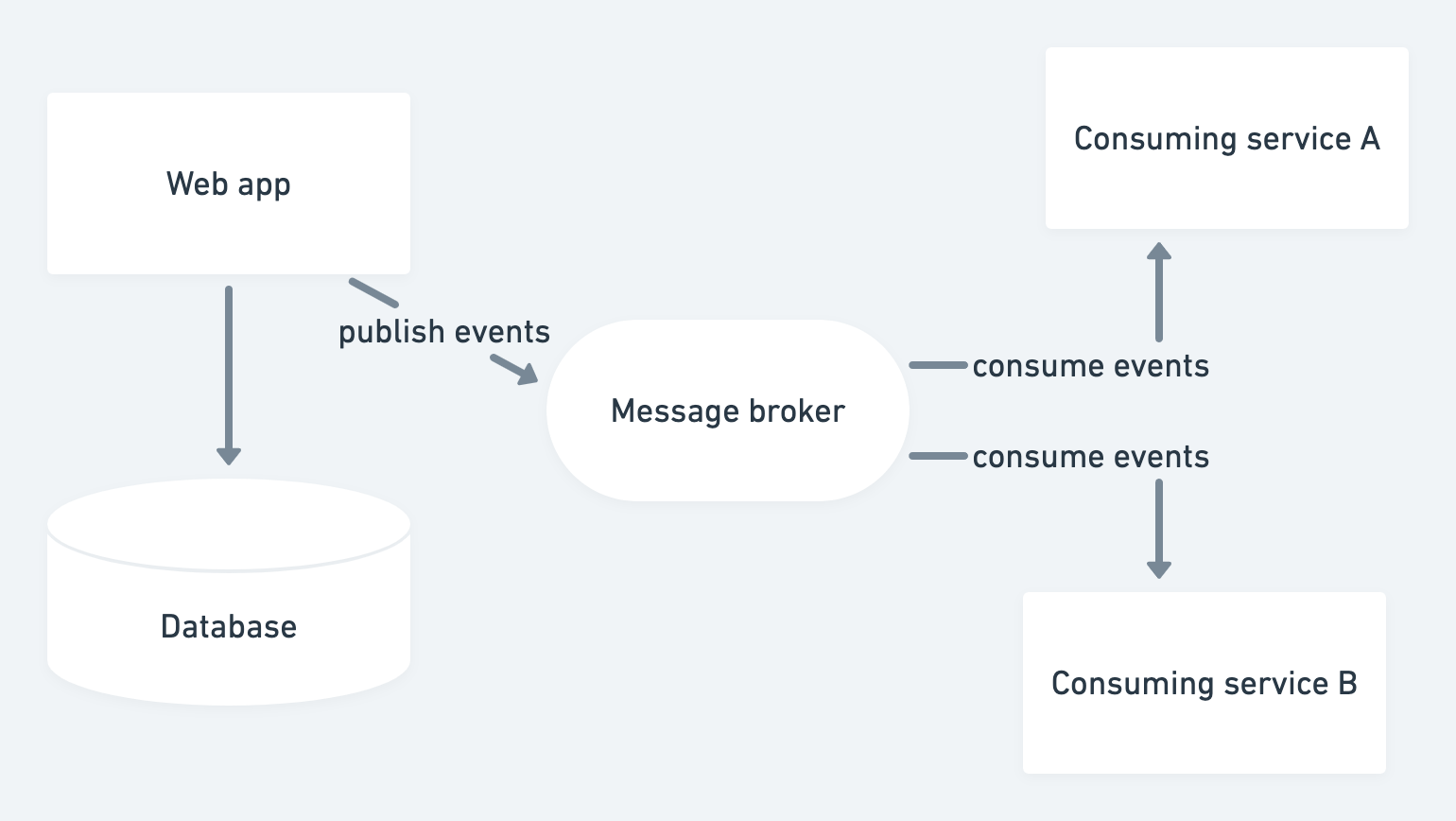
Typical event sourcing
In a typical system, we have a master web application which publishes change event notifications to downstream consumers. This allows us to keep our downstream systems in sync, in real time, with the web application. While the web application has no knowledge of the downstream systems. This image shows a typical system architecture:
Usually we have to write dedicated code in our web app to construct change events and publish them to our message broker. If we are introducing event sourcing for the first time we may have to introduce this “event publish” code in many places. This basic architecture was used (in my time) at both Stripe and Heroku.
Heroku went through a number of iterations of its internal event sourcing service. One of the later iterations used Kafka as the message broker. Many downstream systems and services were enabled with this architecture including webhook delivery and our customer accounting system.
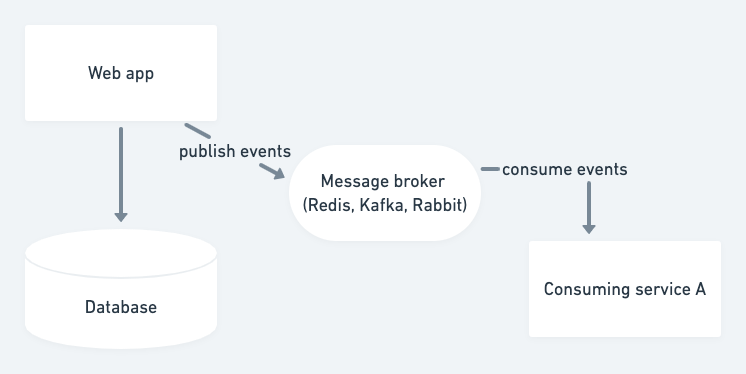
Instrumenting the ORM
When we built the Heroku Connect product, we saved some coding effort by instrumenting our ORM to automatically generate change events for every model mutation. This avoided having to manually write event publishing code, and also meant that new models would automatically start publishing changes to the event stream.
However, this approach doesn’t solve every problem, because at some point most applications will introduce some pathway by which data is modified in the database while bypassing the ORM. If you need to hand-code a bulk operation in SQL, how will those changes get published to your event stream?
Change-data-capture
More recently folks have been introducing change data capture systems. In this architecture, we capture data modifications at the database and publish them to the event stream. This approach solves two problems. We no longer need to write or maintain event publishing code, and we will publish changes made to the database no matter whether those changes work through the ORM or not.
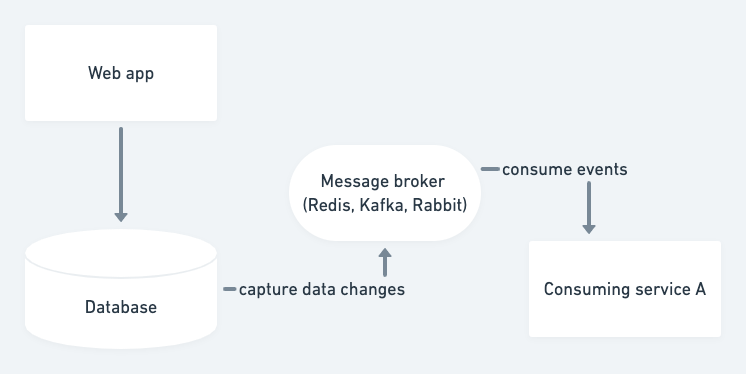
No-code event sourcing with Postgres
In the past we have hade to use mechanisms like triggers or listen/notify in order to capture changes inside the Postgres database. However, Postgres 10 introduced logical replication. This mechanism was created to replicate changes from one Postgres server to another. However, we can observe that logical replication is in fact exactly this change-data-capture mechanism we are looking for. If we could easily decode this event stream we could react to any changes occuring in our database.
Recently the startup Supabase introduced a new tool Realtime built to make this job easy. Realtime is an Elixir app which connects to your Postgres server, listens to the logical replication channel, and re-publishes changes over websockets. The obvious use-case is to push changes out to the web browser, but it’s also easy to listen to that websocket with a server process.
I tested this out with a Reddit Clone application. After setting up my local database with rails db:setup, I needed to configure my Postgres server to enable logical replication. Checkout the realtime repo for instructions.
First I enabled logical replication:
$ psql
> ALTER SYSTEM SET wal_level = logical;
> ALTER SYSTEM SET max_replication_slots = 5;
then I created a PUBLICATION for the realtime consumer:
> CREATE PUBLICATION supabase_realtime FOR ALL TABLES;
then I ran realtime just using its Docker image:
docker run \
-e DB_HOST='host.docker.internal' \
-e DB_NAME='wiki' \
-e DB_USER='scottp' \
-e DB_PASSWORD='' \
-e DB_PORT=5432 \
-e PORT=4000 \
-e HOSTNAME='localhost' \
-e SECRET_KEY_BASE='SOMETHING_SUPER_SECRET' \
-p 4000:4000 \
supabase/realtime
and finally I adapted the Node.js example from Supabase to print change events to the console:
const { Socket } = require("@supabase/realtime-js");
const REALTIME_URL = process.env.REALTIME_URL || "http://localhost:4000/socket";
const socket = new Socket(REALTIME_URL);
// Connect to the realtime server
socket.connect();
// setup a listener to the enture 'public' database schema
const SchemaListener = socket.channel("realtime:public");
SchemaListener.join()
.receive("ok", () => console.log("SchemaListener connected "))
.receive("error", () => console.log("Failed"))
.receive("timeout", () => console.log("Waiting..."));
SchemaListener.on("*", (change) => {
console.log("DATA UPDATE", change.record);
});
Conclusion
This is a very cool approach to enable event sourcing from your Postgres database with no changes, and pretty minimal effort. This architecture can be used to loosely integrate downstream services, or to route real-time application changes to your front-end.
