Starting in the middle of 2022, we embarked on a large migration project at Tatari to upgrade our core data processing platform. At that time we were running a traditional warehouse architecture where all of our big data processing was running on Amazon Redshift.
The warehouse was an evolution beyond our original “startup” architecture where we had stored everything in Postgres. Moving to Redshift gave us access to our first scalable OLAP database (Online Analytics Processing) and enabled us to support over 100 customers processing terabytes of metrics data each day.
Over time, however, we had run into a number of challenging issues running production workloads on Redshift:
Performance issues
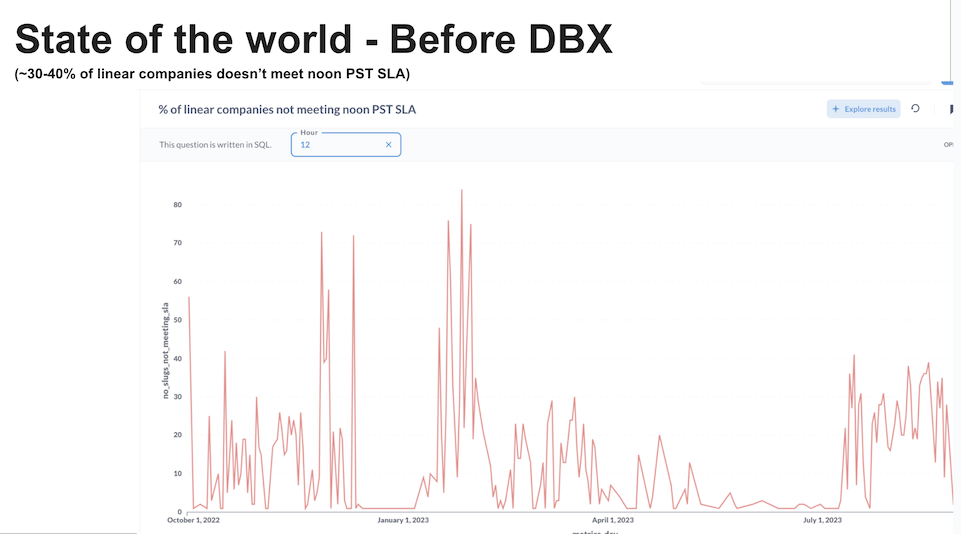
Although Redshift is designed as a multi-node system which supports both vertical and horizontal scaling, we were regularly running into scaling and performance issues as our workloads increased. Generally the solution to these problems was to “scale the cluster” by adding more nodes. This usually worked, but we got the strong impression that Redshift scaling wasn’t linear with workload demand. Architectural issues like the shared “leader node” seemed to resist easily scaling out of performance issues.
The following chart shows how often we were missing our SLAs for delivering next-day metrics to some customers:
Rapidly increasing costs
Of course as we scaled our production cluster, costs scaled too. The basic design of Redshift at that time (before the “serverless” option) meant that scaling your cluster required adding more persistent nodes and then paying for those nodes to run 24x7.
Redshift design also pre-dates the move to separating storage from compute, so adding nodes adds both storage and compute to your cluster, and requires the cluster to redestribute data when the cluster grows.
The result is that resizing the cluster is a “big deal” operationally, and incurs significant ongoing costs.
Everything is SQL
Redshift is great at running SQL queries over large datasets. While SQL provides an effective lingua franca for a data-intensive company like ours, its also has its limitations. From the start Tatari has had a strong data science group, and our proprietary analytics require mathematical complexity that stretches well beyond SQL’s traditional strengths. Running our workloads on Redshift meant constantly having to translate Pandas/NumPy/scikit code into SQL idioms.
Over time this translation cost became increasingly burdensome as the “production implementation” diverged from the original and required ongoing re-translation as models evolved.
Looking to the future
As Tatari grew our dedicated data engineering team we had gained more big data experience from folks that had used both the Hadoop and Spark ecosystems. We had started dipping our toes into the Spark waters at the end of 2021. As we got into 2022 we started to more seriously consider the idea of adopting Spark as a critical technology.
We also considered next-generation warehouses like Snowflake. The biggest advantage of that path was that the evolution from Redshift would be more natural, and we expected that Snowflake architecture would effectively address our scaling challenges.
Spark wins out
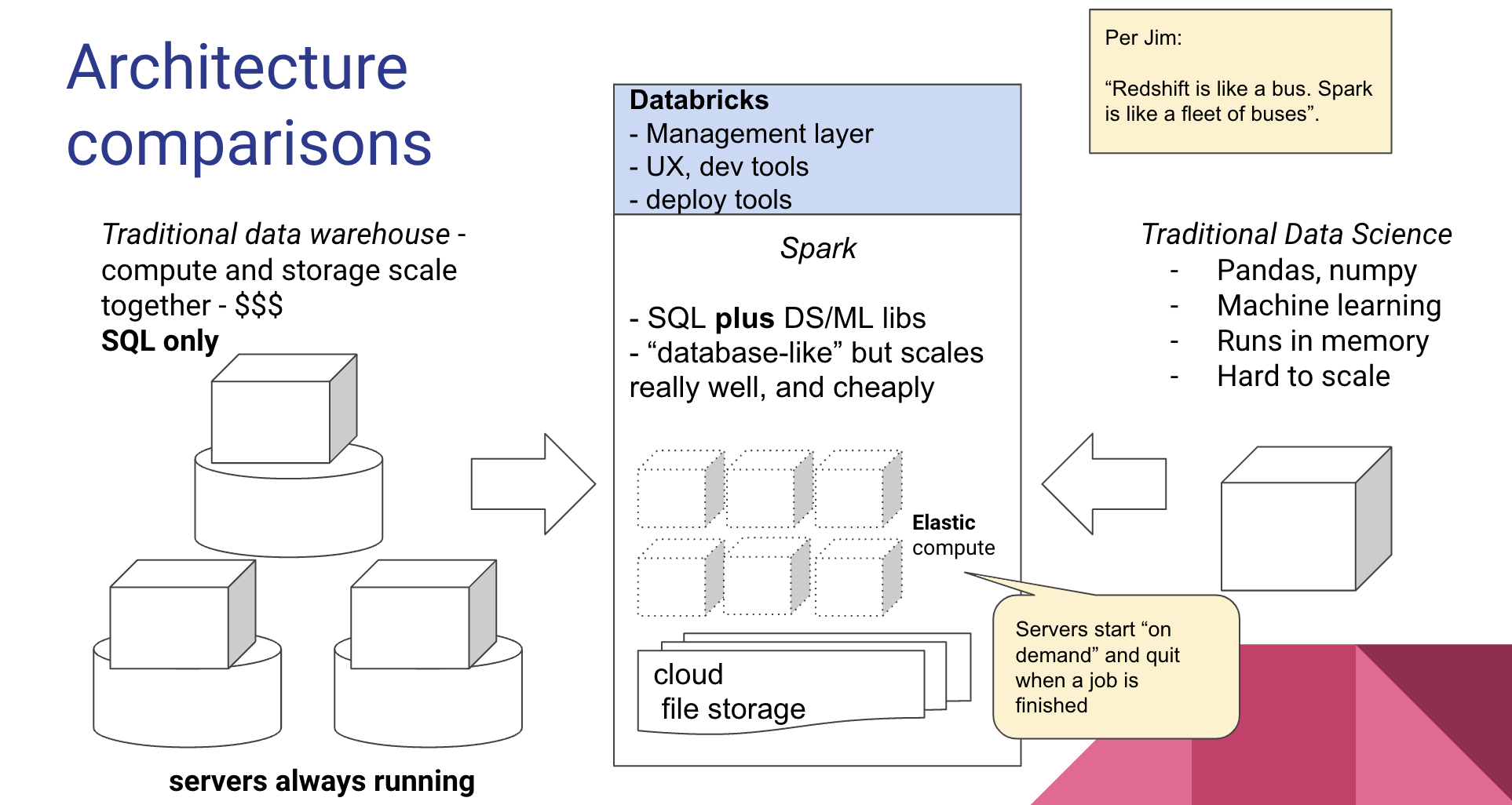
However, moving to Spark offered both the promise of solving our scaling challenges while also moving us to a platform that could be shared between our Data Science and Data Engineering groups. We were also excited to have better platform support for our growing Machine Learning team and its work. By shifting away from data warehouse to a data lake we would open up the kinds of computation and library support that we could run over our data.
We operated our own workloads on open source Spark in early 2022, but once we committed to shifting wholesale onto the platform we decided that working with a managed vendor would be much easier. Databricks as the default offering for production Spark was a straightforward vendor choice.
In the middle of 2022 we started seriously evaluating the Databricks platform and planning our platform migration.
Kicking off the migration involved a lot of explanation and evangelism around the company. I used this slide to explain the scalability advantages of moving to Spark, and how that platform would help bring our Data Science research and development into a shared platform with engineering:
The migration view from above
Most of our energy for the migration would go into planning, remodeling and rebuilding our data pipelines on the Databricks platform. However, a technical migration of this size requires a lot of elements beyond that core work:
- Selecting and negotiating with the vendor
- Evangelizing the migration to internal stakeholders outside of engineering
- Planning and coordinating with heavily impacted teams like our Data Science and BI groups.
- Training developers and data scientists on Spark and Databricks
- Managing workloads and costs during the period when we would need to operate both our new and legacy platforms
In our next post, Mala Munisamy will delve into some of the challenges and strategies that we employed on our successful Spark migration journey.
