
Reports are one of the core components of the Tatari product. They not only serve the purpose of telling us how well a media plan went, but also serve a variety of other purposes. They aid us in communicating with clients about key metrics and areas to focus on, and allow their automated systems to ingest data for comparisons and visualization.
As with most companies, Tatari reports started out as Excel workbooks, Google Sheets, and CSV files emailed or shared with clients. However, as we started getting more and more clients, and as clients grew, there came a point where creating these reports and sending them through email or as Google Sheets became increasingly unwieldy. Some reports exceed the size limits of email, and make viewing the report in the browser a slow and frustrating experience. In addition, there was also an increased demand in the ability for automated systems to process these reports, which a workbook format doesn’t satisfy very effectively.
To solve these issues, we decided to share reports directly with clients using a technology that is designed for storing and distributing bulk data and is compatible with most data processing systems: Amazon S3. Today, Tatari reports are uploaded into a bucket in S3 which is then accessible from the browser, command line, or in applications using standard tools. In this blog post, we will focus on the management side of this sharing system: how we organize reports, and how we automatically grant access to reports in a way that clients can manage themselves, so regardless of company and IT department size, they can find a solution that fits their needs. We will have another blog post coming up, detailing how we version and ship changes to existing reports.
Who owns the bucket?
One of the first decisions we had to make was who would be responsible for managing the report data, or who would own the S3 bucket that reports reside in. There were 2 decisions here, each with pros and cons:
- Clients own the bucket, and provide us with credentials to write to their bucket
- Advantages: Clients can set up the bucket however they like and grant permissions to employees
- Disadvantages: If there is an issue or error with credentials or S3, we lose the reports that were generated during that time. Smaller clients need to deal with S3 and IAM administration, which they may not be familiar with
- Tatari owns the bucket and clients provide us with credentials that they want to read from the bucket
- Advantages: If there is an error with reports, Tatari can regenerate all reports during that time frame easily. S3 administration is handled by us, and there is a history of all reports that can’t be accidently deleted.
- Disadvantages: We have to manage all the users and clients can’t just give anyone they want access to the bucket on their own.
One of the key considerations for us was how to handle data retention. We think that it is very important that we keep all the old reports in an accessible form to allow us to review potential discrepencies and investigate issues. In addition, it alleviates a lot of customer support requests where clients have misplaced or lost reports. As a result, we decided to host the bucket, and produce an interface to allow clients to grant access to their data.
Sharing bucket setup
Each client is able to configure access to the S3 bucket via a page on their dashboard. So although the buckets are owned in the Tatari account, each client can grant access to reports to their own AWS users.
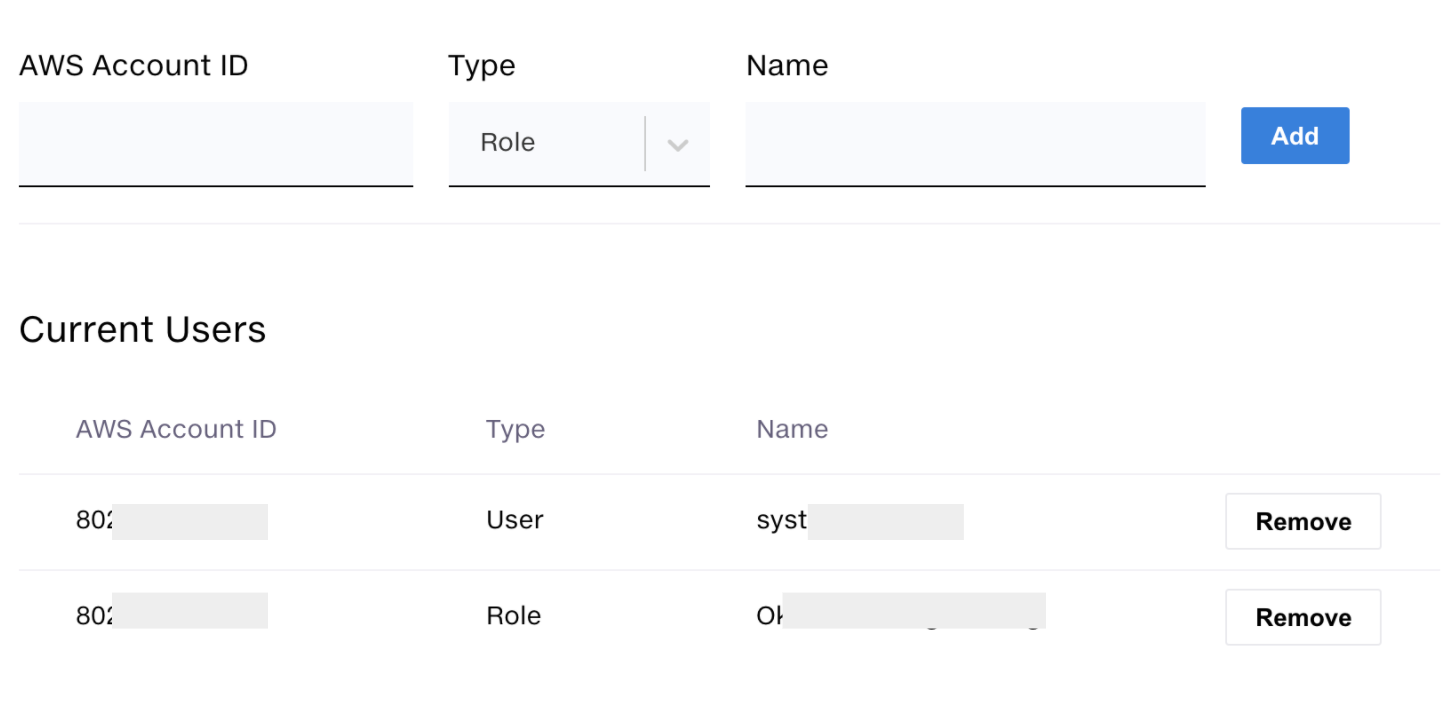
Permissions and Policies
So how did we setup this bucket restriction and login system? We went through two iterations with this system. Initially we used the S3 Bucket Policy to restrict what buckets and prefixes a given user would be able to access. To grant access to a given user to a folder, we would add a statement in the S3 bucket policy granting that user access to the ListObjects and GetObject calls for files in the folder. There are a few issues with this method that became apparent as the number of users grew:
- You can’t just edit one statement in an S3 bucket policy. The entire policy is a single block, which means that adding and removing users can potentially affect other users. This is pretty dangerous if there is a bug with the policy generation process.
- Policy principals are validated. This means that if there is a user that we previously granted access to using the bucket policy that was deleted, we would have to remove that user’s principal from the policy before AWS will accept the policy. Since most of the users in the policy are users we do not control, this means that clients can cause the policy to become invalid. Combined with the limitation above, this becomes a serious problem.
- There is a size limit on S3 access policies. This is 20KB and it applies to the entire bucket. When we migrated off this system, we were using about 9,000 bytes, which means if more clients added more authorized users, or we signed more clients, we would have to shard the bucket.
These issues were okay for the first iteration of the product, but it was very clear that this solution wouldn’t scale. The isolation problems were just a disaster waiting to happen, and the limits to policy size set a time limit on this method.
AssumeRole and IAM
There is a second way to delegate access to S3, and that is through IAM policies. IAM policies are the reverse of S3 bucket policies. Where S3 policies describe who is allowed to access what in that specific bucket, IAM policies specify what objects a given user can access. They effectively allow us to define permissions from a different point of view. However, the main difference we were interested in, is that there isn’t really a limit to the number of IAM policies you can have. The soft cap is 5,000 by default on fresh AWS accounts, but this can be increased by asking support. This solves the third problem above. The other main problem was the issue of invalid externally supplied principals breaking our ability to apply policies, which when combined with the non-client isolated policies, became a significant challenge.
We solved this issue using the AssumeRole API. AssumeRole allows a given user or role to take on the identity of another role. When you do this, you effectively log on as that other role. This works even across accounts. To remove the reliance on an externally supplied principal, we instead now create a role that we manage for every client under our account. This role is allowed to access the client’s data in the S3 bucket. Finally, to allow clients to log on as this role, we apply a policy which takes the authorized user list they specify in the dashboard above and allows them to log in as this special user. Clients themselves can then decide how they want to use their own users and roles to further delegate access.
This method of authentication works in the web-based AWS Console, the command line, and in applications, which provides the maximum flexibility for our clients, allowing them to use their data in whatever tools work best for them.
