
A core tenant of my design philosophy can be boiled down to the phrase “choose boring technology”, and it is ~literally always~ in most cases the correct choice! I think a crucial extension of Dan McKinley’s idea of choosing the boring technology is to keep technology modular. That was the architecture that Linus Torvalds used to build Linux into the juggernaught that it is today, and not adhereing to separation of concerns can cause otherwise boring software to become big, burdensome and complex.
Choosing the boring technology brought Tatari a long way, our core monolith powering the backend services has been built up over 7 years and tens of thousands of programmer-hours. Since day one, that core monolith has been Python sitting on top of a Flask webserver and a PostgreSQL database (RDS actually, since it’s in AWS), suitably “boring”. We have spent a few of our “innovation tokens” on fancy technology, primarily in the name of site reliability like airflow (which replaced Cron), React (which replaced our flask-admin interface), Clickhouse (which freed up a whole heck of a lot of traffic from our OLTP database), and Kubernetes (because web scale!) but for the most part the platform has proved remarkably resilient throughout the years.
That’s a strong start, but like golf it’s all about the follow-through. The monolith has allowed us to plop all of our concerns in one big pile. An old platform means lots of tests, lots of dependencies, lots of process; a confluence of concerns means that programmers start to step on each others’ toes. Builds start to take longer, the stack becomes more complex to understand, diagnose and debug when things start to go sideways. In the aggregate developer experience starts to become worse, iterations take longer, it can be death by a thousand paper-cuts. How do we use our mindset of boring simplicity to get ourselves out of this mess?!
Enter the Media 👏 Planning 👏 Service 👏
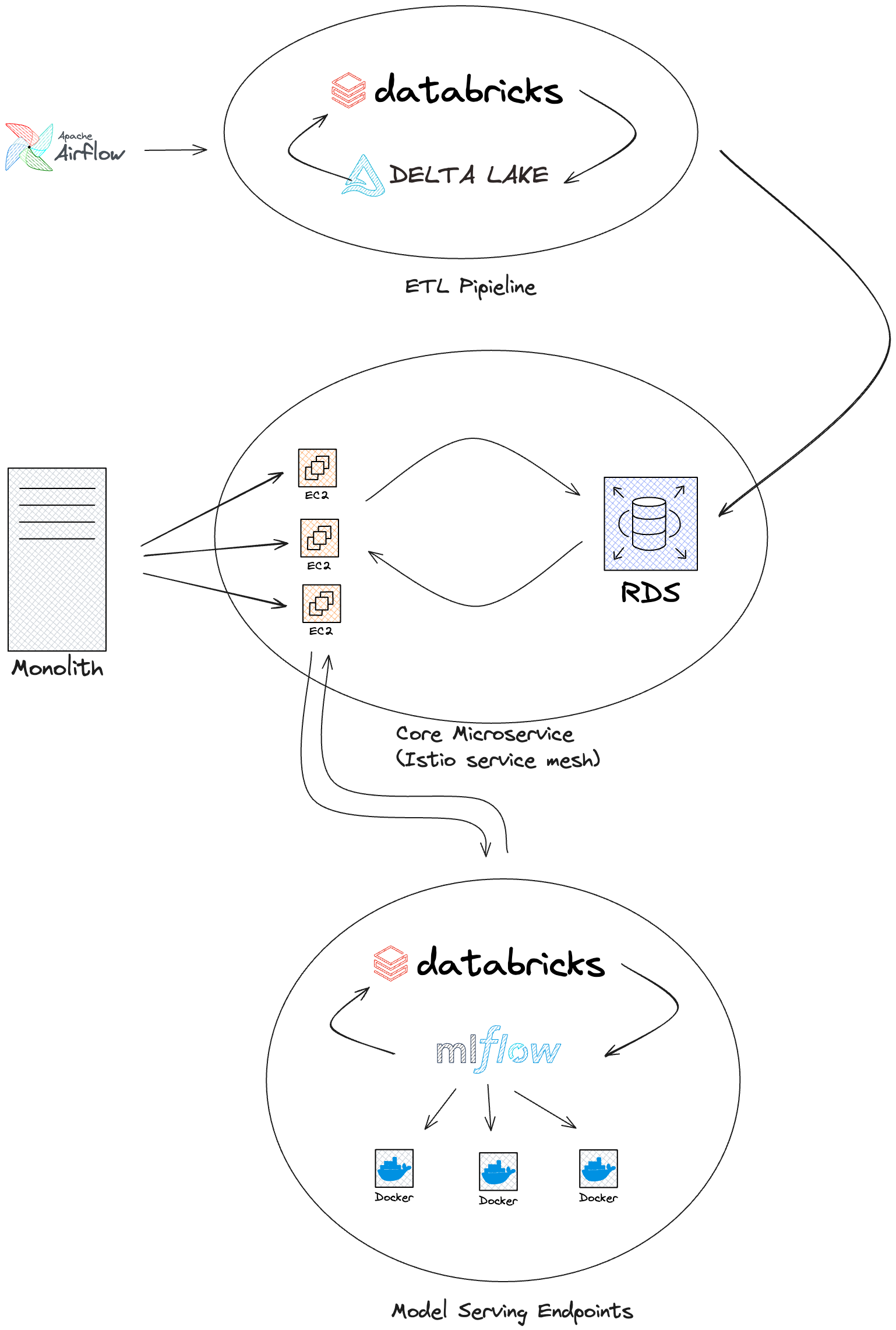
Luckily, developer experience and iteration speed are core priorities for engineering leadership at Tatari! When we started thinking about how we were going to integrate more AI/ML backed products into our platform, we were at a crossroads. Either we continued to build into the monolith which could compound the problems we were already experiencing or we go down the route of micro-services. While it’s easy to be wary of going down the micro-services route (there are many many horror stories of micro-service hell), we knew that continuing to build into our monolith (with 20+ minute build times already) was to hamper the productivity of new developers and stymie cross team collaboration.
Tatari has been a leader in the advertising performance prediction and measurement, but with the introduction of the Media Planning Service the engineering team chose to rethink our prediction platform architecture to enable quick model iteration, high availability, and seamless onboarding for easy collaboration between engineering and data-science. Que boring technology! We reached for the tried-and-true stack of Python and PostgreSQL (again, technically it’s RDS, but you know, same-same), with lots of the complexity we encountered in the monolith pushed out-of-band to ETL pipelines.
Long running measurement query? ETL! Massive datasets with even larger joins? ETL! We opted to have our ETL pipeline do lots of the heavy work and drop post-processed denormalized data into the Postgres database for easy data discoverability and low query times. Now the astute might say, “ETL pipelines are great and all, but what if you need real-time data?”, and we’ll get to that in the model serving section. The nitty-gritty of the ETL pipelines is that they all function by running batch jobs with PySpark or SQL queries (executed in Spark) with delta-tables holding all of the data in a databricks hosted spark environment. That creates a dataframe that we can either store in the delta tables if it’s needed in other jobs or exported to our Postgres instance via a COPY operation and red-black deployment for zero database downtime. Shout out to Tatari’s data-platform and site-reliability engineering teams for the heavy lifting to support that little maneuver.
In addition to the “innovation tokens” we spent to support that ETL pipeline, we still have airflow for job orchestration, and we added the complexity of docker-compose to encapsulate the new service, a whole lot of lines added to the Kubernetes manifest, and some fancy networking with an isto service mesh to ensure secure cross-platform communication via the the sole ingress channels of gRPC or kubectl. That’s a lot of complication, but crucially they sit beside the core service, separated from it as their own concerns. These complexities are not necessary to understand when onboarding to the platform, it’s just a Python process running on top of a FastAPI server sending queries out to a PostgreSQL database… easy! You can start it up locally and toss a breakpoint here or there to understand how it works intuitively, just like that script for the LLM agent you made six months ago and got bored of and keep telling yourself you’ll pick up again… maybe I’m projecting. I want to emphasize again, separating out big queries into an ETL pipeline rather than having all these impossible-to-read performance-tuned queries in the codebase, making the docker-compose so that other services are easily addressable rather than needing a third party service like vault or similar to find them allows for a simplicity on the platform that allows for easy development.
gRPC
In the vein of the boring technology mindset, we could have chosen to just keep writing REST APIs. Instead, we chose to use gRPC as the interface between the caller and the service. gRPC is a high-performance, open-source universal RPC framework. One of the main reasons on top of all the fancy HTTP/2 stuff is that it’s built on top of protocol buffers, which is a language-neutral, platform-neutral, extensible mechanism for serializing structured data.
message Person {
string name = 1;
int32 id = 2; // Unique ID number for this person.
enum PhoneType {
UNKNOWN = 0;
MOBILE = 1;
OTHER = 2;
}
message PhoneNumber {
string number = 1;
PhoneType type = 2;
}
repeated PhoneNumber phones = 4;
google.protobuf.Timestamp last_updated = 5;
}
message AddressBook {
repeated Person people = 1;
}
But how do protos help? At some point in every developers career as they work with something like REST, they will inevitably make a mistake in the request or response body. Maybe you forgot to add a field, or you added a field that you didn’t mean to, or you changed the type of a field. Or you’re trying to implement a client to the server and don’t know what you can and can’t send. With REST, you have to go look at the code to figure out what the request and response bodies look like. With gRPC, you can just look at the proto file, like the “Address Book” message above, and see exactly what the message bodies look like; it’s a definitive contract between the caller and the host system. The request and the response will each have a proto file associated with them.
This has been a huge win for us, as we have many different teams interacting with the service, plus there’s considerably less opportunity to make an unintended change given the rigid interface that protobuf requires. Additionally, we send a lot of numerical data back and forth, and protobuf is a safer, more efficient way to serialize that data when compared to JSON (ever forget to send 100.0 vs 100 when trying to send a float?). Our devs don’t have to write any code to serialize or deserialize the data, it’s all handled for them and translated into easy to use Python objects (json_format.MessageToDict for the win!).
Truth be told, it wasn’t all sunshine and roses getting used to the new paradigm. The boilerplate code that accompanies protos and gRPC can be a lot, and debugging calls over gRPC is an added step of complexity where most programmers are comfortable debugging a REST call already. Proto definitions are rigid and can be tricky, for example in the Address Book message note that the 0th element of an enum should always be unknown, as that will be the default value if the field is unset and cannot be set explicitly by the caller. Default values will also be set for empty fields depending on data types, 0 is the default for ineger types for example. This default behavior can make it very difficult to determine if a field is null or empty which was source of bugs for a little while, however this was easily remidied by deserializing to dict or json. For more on proto pitfalls, check out Manuel’s post on Kreya which we found helpful.
Overall leveraging strict data contracts via protobuf and gRPC have been a huge win for us. Discovery and iteration using the API is much easier as proto files are inherently self-documenting and devs can simply pull the gRPC libraries from github and start using the service via the protobuf stub.
Model Serving
In addition to the choice of using gRPC, we also made the decision to have our numerous ML models served independently as their own service. While we could have rolled our own, we ended up choosing Databricks Model Serving as our model serving host. This allows us to have a separate service for each model, and allows us to scale each model independently. Each model can then be developed independently with their own requirements (a linear regression model takes far less compute than a LLM for example). Our Media Planning Service is then only responsible for the interfacing to the Databricks model endpoints. Our R&D teams can focus on building great models and not be constrained by the service that serves them or the infrastructure that runs them.

This separation of concerns has allowed us to iterate quickly on the service and the models, without having them get in each others way. Ever try to deploy your own models and then end up in dependency hell with all the scientific libraries? We have, and it’s not fun, this LightGBM package requires this arrow version, ad nauseam. Databricks Model Serving has allowed us to avoid that trap entirely, and we can just focus on the service and the models separately. Databricks also allows us to elastically scale our model serving endpoints independently, so if we have a model that’s getting a lot of traffic, we can scale it up without having to scale the entire service. If we have a model that’s heavy compute wise but not used often, we can scale it to zero until we actually need to use it more similar to a batch job.
What’s next?
In our continued effort to make things boring and easily repeatable, we’ve been spending lots of time working on cookie-cutter templating for our ML models, which will allow us to type a few commands and have all the boiler-plate for a new model ready to go! This will give our data-science team the freedom to rapidly iterate on new models and improve current models without having to learn a whole new stack.
Conclusions
Choosing boring technology is a solid north-star, but starts to struggle at the extremes. I think a good addition to this philosophy is the idea of keeping technology modular, otherwise your “boring but good” software become the dreaded “boring but bad” enterprise software 😱! Keeping the core app simple and separating the complicated parts to live beside it has been a robust architecture so far. Splitting out the microservice was a huge investment from our platform teams, but we’re beginning to reap the rewards of that investment with whole new level of cross-team collaboration and improved velocity! All of software architecture is a series of trade-offs, be it for scalability, observability, cost, complexity, or otherwise, but keeping things simple and modular makes a solid foundation for great application platforms.
