
Summary
This blog details how Tatari scaled its OLAP (Online analytical processing) platform using ClickHouse to handle the growing demands of large-scale, high-dimensional data in TV advertising analytics. Previously using a traditional data warehousing model with Amazon Redshift and SQL, We shifted to a Databricks/Delta Lake/Spark architecture to scale the data processing. Once we solved the data processing challenges, data access & updates to Aurora PostgreSQL became a bottleneck, requiring a new OLAP architecture for data upserts and faster query access to the customer’s dashboard and reports. The blog explores challenges faced in the previous system, the necessity for a new database architecture, and the roadmap for migrating to this new system.
Previous Architecture with RDBMS
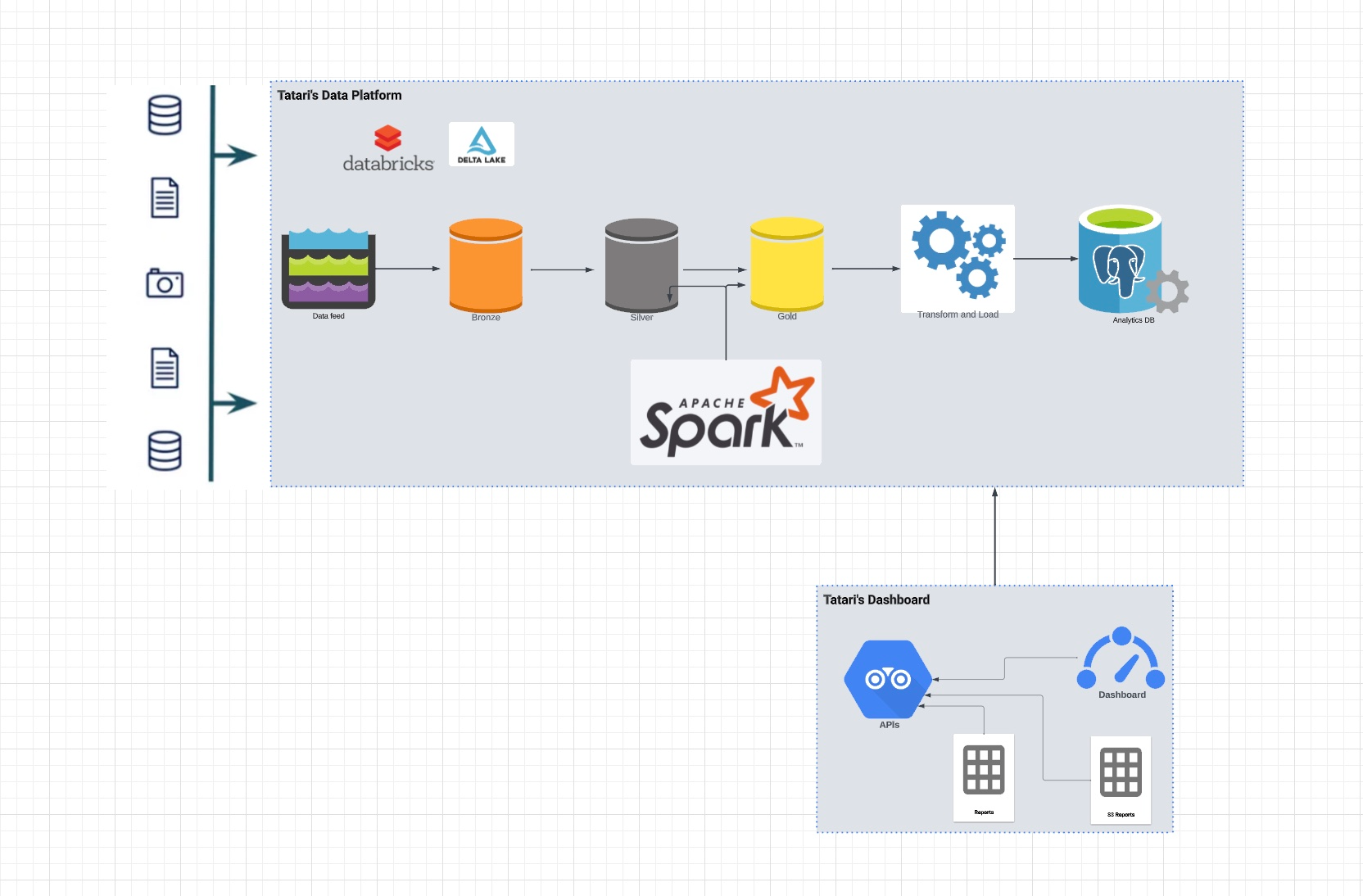
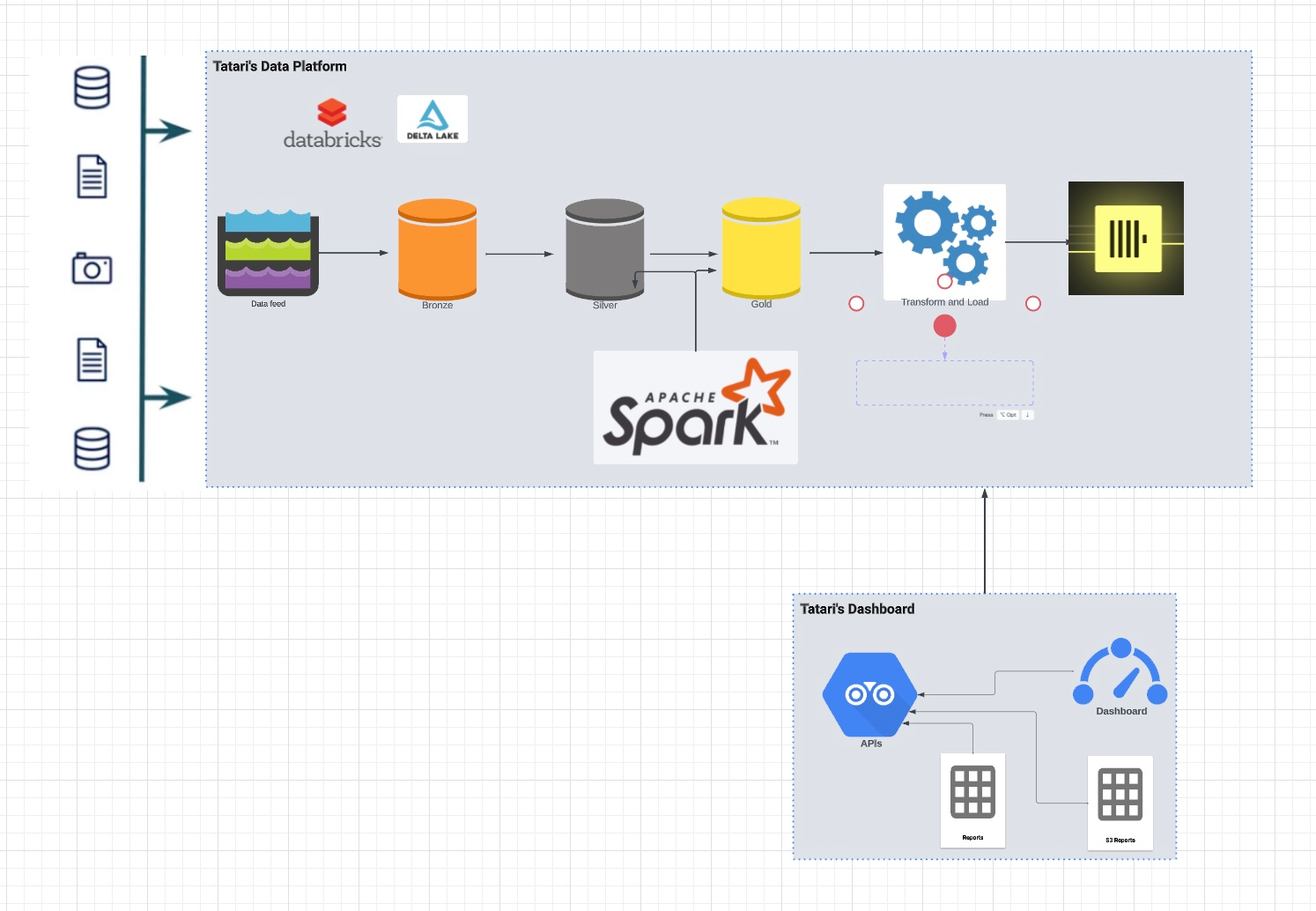
Since mid-2022, Tatari has significantly transformed its data processing framework. Moving away from a traditional data warehousing model reliant on Amazon Redshift and SQL, we embraced a Databricks/Delta Lake architecture and Spark computing workloads. This shift has enabled us to scale our data processing capabilities horizontally to meet increasing demands. In Scott Persinger’s Tatari’s Next-gen Data Platform, he set the context for Tatari’s next-gen data platform.
Currently, we process approximately 100 million user events daily. After processing, the data — which spans various periods (day, week, month, quarter) and includes around 250 dimensions such as creative elements and Designated Market Areas (DMAs) — is stored as Parquet files in Delta Lake. This data is then upserted into a PostgreSQL database, which Tatari’s reporting API retrieves for display on customer dashboards.
A system’s performance is only as strong as its weakest link. In our case, the upserting of around 600 million rows into single node Autora PostgreSQL emerged as a bottleneck, frequently leading to data outages and adversely impacting our customers. Initially, we implemented a temporary solution by sharding files before upserting them into PostgreSQL. While this provided temporary relief, it did not fully resolve the underlying scalability issue.
Our roadmap to improve our measurement capabilities will push our daily processing requirements towards 1B rows. This goal necessitates a new OLAP (Online Analytical Processing) architecture capable of efficiently handling both writes and reads from Delta Lake datasets, thus surpassing the performance limitations of traditional RDBMS systems like PostgreSQL. The previous architecture involved upserting into PostgreSQL for reports and dashboards.
Challenges and the need for a new database & data access architecture
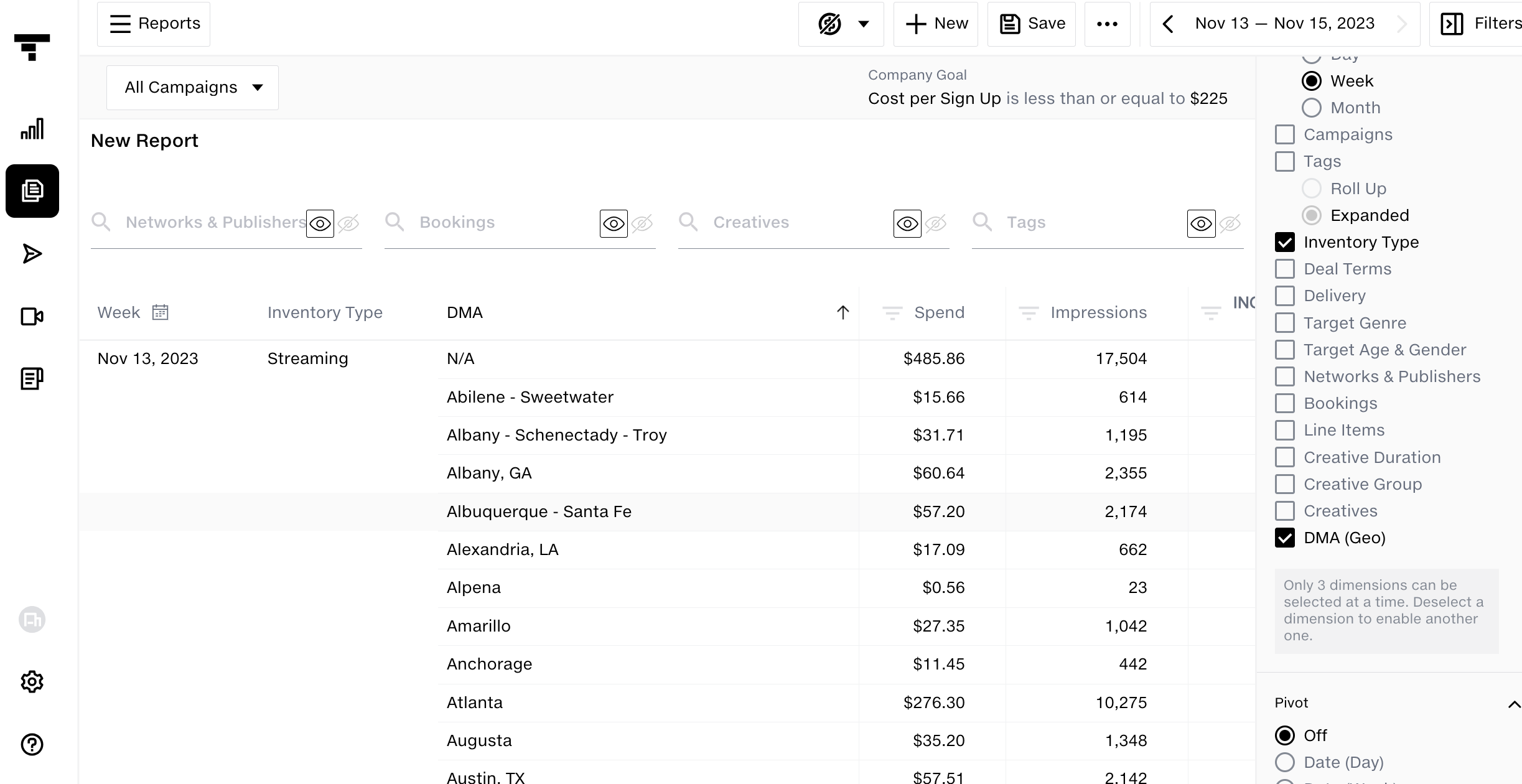
As we experienced rapid customer growth and improved our measurement capabilities through 2021 and 2022, the complexity and volume of our data increased exponentially. This growth manifested in an expanded number of dimensions in the order of ~400, combinations of these dimensions, and the overall volume of data required to serve our customer base effectively as we added more breakdowns of metrics data, such as conversions by DMA and audience. Relying on PostgreSQL as our primary database and query engine became increasingly untenable under these conditions. We projected approximately 1 billion rows to be inserted daily into the PostgreSQL database that serves the measurement dashboard and reports and storage in the order of couple billions for historical data beyond 30 days. Consequently, our commitment to next-day measurement Service Level Agreements (SLAs) began to falter, underscoring the need for a more robust and scalable data handling solution.
Real-time calculation needs
Before implementing the new architecture, each dimension for measurement metrics had to be calculated using a proprietary data science model. The complexity escalated as the number of dimensions increased, particularly with audience and geographic breakdowns. Often, the dimensions that needed to be calculated and reported on were not known in advance, making pre-calculating all 500 dimensions and their combinations impractical. Furthermore, maintaining these pre-calculations would have added additional complexity. This complexity highlighted the need for aggregation at the query level for secondary dimensions and underscored the necessity for a database access model capable of managing such demands.
Capacity planning and projection
After defining the scaling requirements for the OLAP and access platform in early 2023, we did a comprehensive capacity planning exercise to meet Tatari’s scaling needs for the future. This planning focused on critical aspects such as data storage, data load size, and Query-Per-Second (QPS) requirements projected for the upcoming years. Our planning model was built upon several critical factors:
- The number of dimensions aggregated and stored in the OLAP database.
- The growing number of customers.
- The volume of data over 30 days, considering that measurement metrics are processed within this attribution window.
Based on these considerations, we meticulously estimated the best, average, and worst-case scenarios for data storage and data load size projections, ensuring our infrastructure is robust and capable of adapting to varying demands.
Goals for the new OLAP architecture
The OLAP architecture is designed to achieve the following key objectives:
- Efficiently manage a substantial volume of data updates, which vary from 600 million to 1 billion rows daily.
- Develop a data model capable of processing metrics in real time.
- Improve the speed of query access to enable faster data retrieval.
- Faster future product enhancements and experimentation
High-level architecture with clickhouse
We conducted a thorough evaluation and benchmarking of high-dimensional OLAP databases, focusing on the above mentioned use cases. ClickHouse emerged as the standout choice, demonstrating superior performance in read and write operations. The processed data is now loaded into the ClickHouse database, from which our reporting API retrieves information to display on customer reports and dashboards.
High-level roadmap for migration
Migrating to a new architecture within a current production system is like switching the engine of an airplane mid-flight; it requires meticulous consideration. The key milestones of this migration included:
- Achieving alignment among product, engineering, and internal stakeholders regarding the current architecture and challenges related to Return on Investment (ROI).
- Projecting future scale and growth.
- Benchmarking OLAP database solutions to meet our anticipated growth and needs.
- Building new architecture components involved transforming analytics to a data model optimized for ClickHouse, ingesting analytics data into the ClickHouse database, and updating the Reporting API to switch the query engine to use data from ClickHouse. This feature switch enabled us to transition datasets and components to the new OLAP architecture gradually.
- Retiring the previous architecture components and removing datasets from PostgreSQL.
- Meticulous QA, adoption of newer efficient query patterns, and cross-team training to support broad adoption.
In forthcoming posts, Tyler Lovely, Harshal Dalvi, and Toussaint Minett will delve deeper into the details of the benchmarking process, the new OLAP infrastructure, and the architecture.
Special thanks to Tyler Lovely, Toussaint Minett, Jim Lyndon, Leslie Rodriguez Garcia, and Dan Mahoney, who played pivotal roles in this initiative, from benchmarking to executing the roadmap.
