
MLOps, or Machine Learning Operations, is an essential framework integrating machine learning (ML) into an organization’s broader operations and development processes. Drawing inspiration from DevOps, MLOps applies similar principles to the machine learning lifecycle, aiming to automate and streamline the development, deployment, and maintenance of machine learned models.
A brief history
Initially, machine learning was primarily the domain of researchers and data scientists, with model deployment often being a manual, ad-hoc process. However, as ML gained traction in industry settings, the challenges of transitioning models from development to production became more apparent. Issues like reproducibility, scalability, and the need for continuous monitoring emerged as critical concerns.
This evolution was paralleled by the rise of “DataOps” almost a decade ago, aimed at streamlining data pipelines. As organizations increasingly integrated machine learning into their workflows, the need for a comprehensive lifecycle development and operational paradigm for ML became evident. Thus, MLOps emerged, marrying DevOps and DataOps principles with the unique requirements of machine learning.
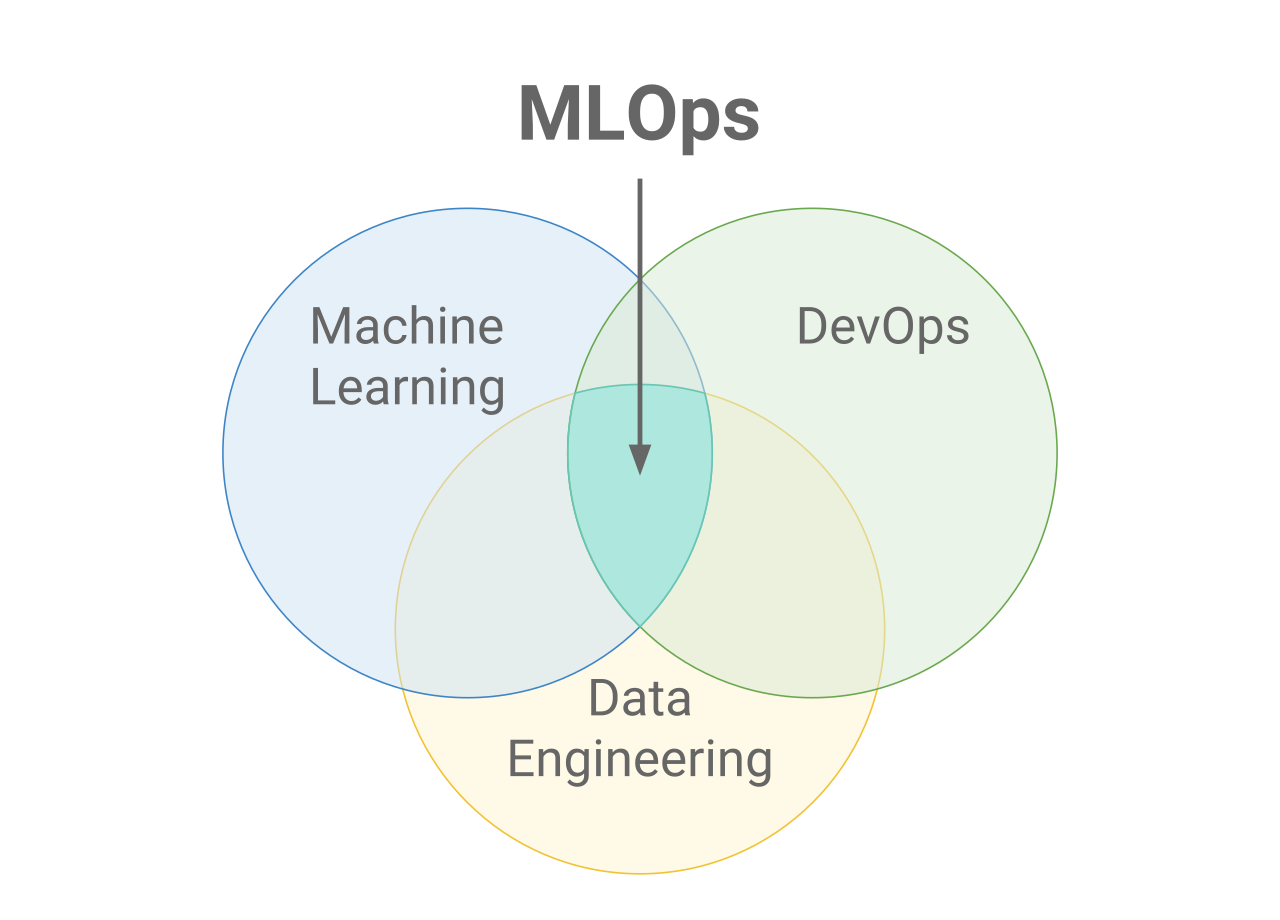
The MLOps Equation = DevOps + DataOps + ModelOps.
DevOps: Involves principles for deploying software, maintaining high availability, consistency, and reliability, underpinned by Continuous Integration (CI) and Continuous Deployment (CD).
DataOps: This blends a process-oriented perspective on data with Agile methods, focusing on improving data quality, speed, and collaboration.
ModelOps: Essentially the machine learning segment of the operational process, ModelOps involves managing the entire lifecycle of machine learning models within an organization. This includes their development, deployment into production, ongoing monitoring, and maintenance. ModelOps also entails assessing model performance based on both technical specifications and business impact, coupled with continuous retraining and systematic updates of the models.
MLOps in Action at Tatari: Roles and Responsibilities
Machine learning backed products are built in a multi-role, multi-disciplined team, just like all our other engineering products here at Tatari.
Data Scientists (DS): Data Scientists are integral in tackling business challenges, diving deep into data analysis, and leading the processes of training, tuning, and evaluating models. They play a key role in identifying the potential improvements and user experiences that can be realized from the data collected, regularly providing the ‘raw material’ for what’s possible in terms of innovation and advancement.
ML Engineers (ML Eng): ML Engineers are a vital link connecting the realms of data science and engineering. They not only ensure that machine learning models are deployed with the precision of software engineering but also possess considerable ML knowledge. This expertise allows them to contribute in ways similar to Data Scientists, especially in the realm of practical ML applications. While their primary focus is on the engineering aspects, their understanding of ML principles enables them to effectively facilitate data access and assist various teams in integrating machine learning applications into our MLOps platform.
Data Engineers (DE): They are the architects behind data pipelines which are essential for ML and downstream applications. Their role is crucial in structuring and preparing data in a way that ensures that the outcomes of MLOps processes can lead to continuous improvement.
Product Managers (PM): Product Managers are pivotal in overseeing the business value generated by the models. They collaborate closely with all team roles to ensure that project requirements are clearly understood and effectively translated into great user experiences.
Engineering and Data Science Managers (EM, DSM): These managers play a crucial role in overseeing people management within the data science and engineering teams. They ensure that these diverse teams not only understand each other’s perspectives and methodologies but also collaborate efficiently. Their leadership is key in steering the teams towards the timely achievement of business outcomes, facilitating a harmonious and productive working environment that aligns with the company’s strategic goals.
Our team structure emphasizes collaborative dynamics, ensuring a seamless flow from data preparation to model deployment.
Navigating the ML Product Lifecycle
Here at Tatari, all assets of an ML workflow (code, data, models) need to be developed (dev), tested (staging), and deployed (production). Each of these stages needs to operate within an isolated execution environment. These stages have different access controls and quality guarantees.
Development - A sandbox for innovation where the risks are lower.
Staging - A mirror of the production environment emphasizing higher quality and limited access.
Production - In this stage we enforce the highest standards of data and model quality, since any human error can significantly impact business continuity. Extremely limited access.
Currently, the latest version of a model within any given execution environment is considered the de facto standard for that stage. Looking forward, we are exploring the idea of having different model stages within a given execution environment. For example, having a production stage of a model within the staging environment. We’ve also come up with some fun possibilities for naming the different model stages to reduce potential confusion. My favorite so far is: dev -> larva, staging -> chrysalis, prod -> butterfly. We are still evaluating the benefit of an approach like this, but it could provide more flexibility in our approach to model iteration.
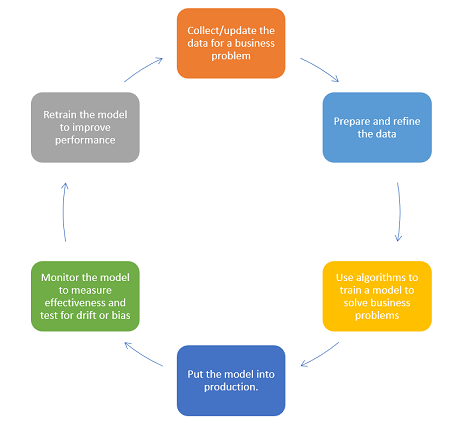
The Model Lifecycle: From Concept to Deployment
In the MLOps framework, each model undergoes a rigorous process:
Data Preparation: Ensuring high-quality data is available for use.Exploratory Data Analysis: Assessing the data’s suitability for addressing business questions.Feature Engineering: Cleaning data and applying business logic for model training.Model Training: Exploring learning algorithms and training configurations, selecting the best model based on technical metrics.Model Validation: Ensuring the model meets both technical and business performance benchmarks.Model Deployment: Depending on the use case, deploying the model for batch inference or online service.Monitoring: Keeping an eye on models for performance degradation or errors, with data scientists ready to update models as needed.
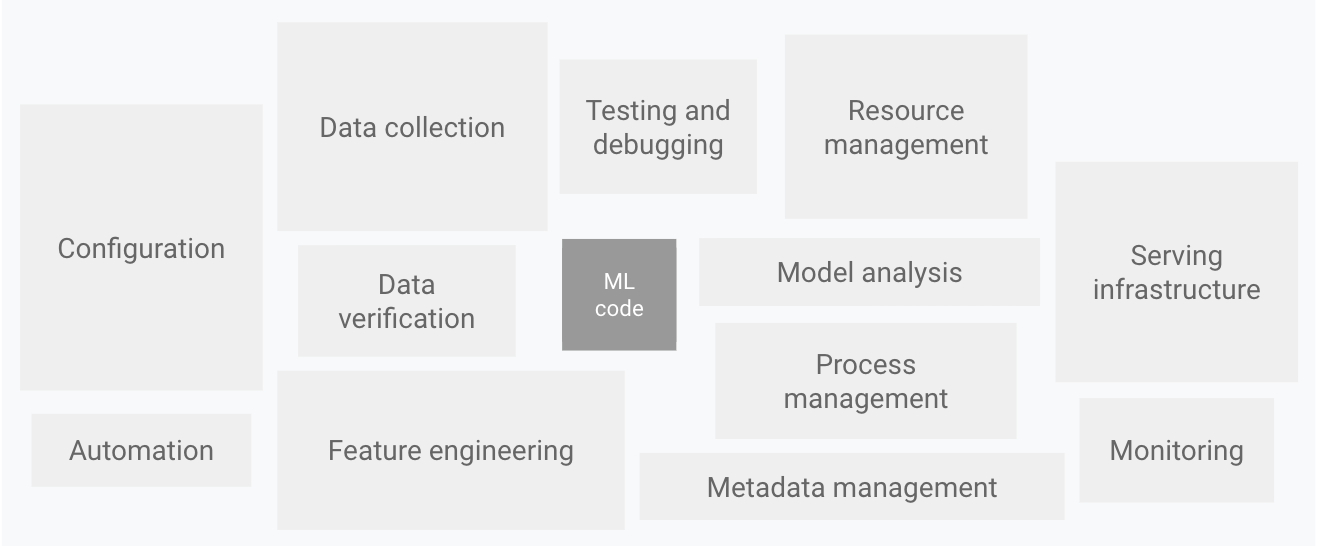
As you can imagine, there’s often more code supporting the model lifecycle, than in the model itself.
Exploring our MLOps Pipeline Stages
Here’s a more detailed look at our model delivery pipeline, which runs within each execution environment (dev, staging and prod)

Feature refresh
In this stage, our focus is on developing and updating code to refine data sets with engineered features. This process is carried out regularly, ensuring that our data remains current and optimized for model development.
Model training
Here, we use the latest data features for training several model candidates, including baseline models. The quality of these models is rigorously tested against holdout data, using metrics carefully chosen by data scientists to ensure that the business problem is being addressed. The resulting models, scores, metrics, and hyperparameters found are all logged.
Model deployment
When a model’s training pipeline is finished and candidate models have been scored, a deployment job collects the latest trained version of each candidate, comparing the scores and promoting the highest-scoring model to become the latest champion model. Metadata such as stats and visualizations can also be logged with the run for manual review if needed.
Endpoint Deploy and/or Batch Prediction
For low throughput, low latency use cases, models are deployed to an online serving system which can take requests, load features from an online feature store, and return predictions. Each request and the resulting predictions are logged for downstream quality assurance.
Inference (batch or streaming)
For high throughput, high latency use cases. This pipeline loads the latest model from the model registry, loads the latest data from the feature store, performs inference and publishes predictions to a persistent dataset.
Model Monitoring
Continuous monitoring is an ongoing process where both the input data distribution and model predictions are scrutinized for consistency and performance. Any deviation from predefined thresholds triggers an alert, ensuring prompt attention to potential issues.
In addition to model and data quality alerts, each job in this pipeline will alert the team to any blocking failures.
We also have several sanity checks in place. For example, we never expect a baseline model to become the champion during a model deployment process. We would be alerted if this ever occurs.
Metric Refresh
Once the champion model has been deployed and real-world predictions have been made, we run an analysis process that generates business-focused metrics that could be highly specific to the problem the model is solving. These can be surfaced in a dashboard and monitors can be built on top of them so that we are alerted if any of the model performance or business metrics go out of bounds.
The Importance of Interdisciplinary Collaboration in MLOps
Interdisciplinary collaboration is the linchpin of effective MLOps. By bringing together diverse expertise from various fields, we ensure a more holistic approach to ML model management. Working together to build an MLOps paradigm that allows us to focus on quickly delivering and scaling experiments to production has unlocked a new level of operational efficiency and innovation. This synergy not only accelerates the development cycle but also enhances the quality and reliability of our machine learning models, ultimately driving better business outcomes and fostering a culture of continuous learning and improvement within our teams.

Conclusion
MLOps has become indispensable in managing machine learning models at scale. As the field of machine learning continues to advance, MLOps practices at Tatari will evolve to meet the growing complexities of organizational needs. Our commitment to pushing the boundaries of MLOps ensures that our model-based products are not just cutting-edge, but also robust and dependable. Future blog posts will delve deeper into specific aspects of model creation and deployment, showcasing the innovative spirit of MLOps at Tatari.
Special Thanks
Members of the Media Intelligence (MINT), Data Platform and SRE teams (in no particular order) for tirelessly forging the path for machine learning at Tatari. Ryan Kuhl, Sean Chon, Tim Morton, Zishu Wang, Jaeyeong Kim, Lucas Miller, Jason Yan, Tommy Hogan Ben Horn, Truxten Cook, Leslie Rodriguez, Patrick Shelby, Willis Shubert Charlie Qin, Jena Vint, Harshal Dalvi, Elizabeth Spear, Ian Jaffe
References:
- https://cloud.google.com/architecture/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning
- https://en.wikipedia.org/wiki/DataOps
- https://en.wikipedia.org/wiki/DevOps
- https://en.wikipedia.org/wiki/ModelOps
